
Die Datenspende-App selbst war nicht quelloffen und hatte Sicherheitsprobleme. Bei der Auswertung der gesammelten Daten setzt das Robert Koch-Institut (RKI) dafür nun auf möglichst viel Transparenz. Die ersten Auswertungsergebnisse sind online und zeigen vor allem, wie viele bislang ihre Daten zur Verfügung gestellt haben – und wie sie auf Deutschland verteilt sind.
Mehr als 500.000 Spender:innen nutzen laut Angaben des RKI inzwischen die App – ungeachtet des schlechten Abschneidens beim Datenschutz. Sie messen ohnehin schon ihren Puls oder ihren Schlafrhythmus mit Hilfe von tragbaren Sensoren, sogenannten Fitness-Trackern, und teilen diese Informationen nun täglich mit den Forscher:innen.
Interessant ist für die Auswertung vor allem der mittlere Ruhepuls, denn daraus lässt sich Studien zufolge auf eine erhöhte Körpertemperatur schließen – so lassen sich Infektionsherde in der Pandemie womöglich schneller erkennen als mit den herkömmlichen Daten des Gesundheitsbehörden. Die Datenspende „ermöglicht uns, die Ausbreitung des Coronavirus besser zu erfassen und die Dunkelziffer der Infizierten drastisch zu verringern“, sagt Dirk Brockmann von der Berliner Humboldt-Universität, der das Projekt leitet. „Diese Informationen sind für Epidemiologen unglaublich wertvoll und helfen, bessere Maßnahmen abzuleiten.“
Wo schlägt das Herz der Bevölkerung?
Bislang ist davon im Blog allerdings noch nichts zu sehen. Die ersten Auswertungen zeigen stattdessen die regionale Verteilung der Spender:innen auf Landkreise in Deutschland. Hier zeigen sich keine großen Überraschungen: In größeren Städten beteiligen sich mehrere Tausende, an der Spitze stehen derzeit Berlin, München und Hamburg. Die Datenernte auf dem Land fällt dagegen eher spärlich aus. Im dünn besiedelten Landkreis Lüchow-Dannenberg spendeten etwa nur rund 160 Menschen ihre Gesundheitsdaten. Ob das ausreicht, um daraus einen statistisch bedeutsamen Mittelwert abzuleiten? Brockmann hatte ursprünglich geschätzt, dies sei ab etwa 100 Spender:innen möglich.
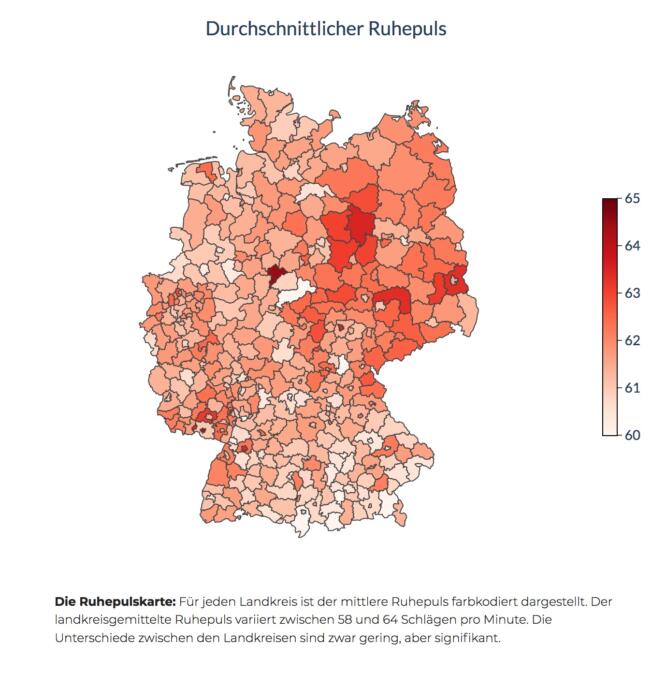
Eine weitere Karte zeigt die durchschnittlichen Ruhepuls-Werte pro Landkreis. Hier fallen die Ergebnisse durchaus überraschend aus, der Ruhepuls in Städten liegt nämlich im Schnitt niedriger als vielerorts auf dem Land. Worauf sich das zurückführen lässt, darauf gehen die Forscher:innen nicht weiter ein. Für sie ist es auch gar nicht so wichtig. Sie verwenden diese Karte lediglich als Referenz, denn wer statistische Abweichungen feststellen will, muss zunächst wissen, wovon sie abweichen.
Danken und erklären
Bislang leistet das Blog vor allem zwei Dinge: Es spricht die Spender:innen direkt an, um ihnen zu danken und sie als „Community“ in das Projekt einzubinden. Und es erklärt Schritt für Schritt anhand der Zwischenergebnisse, wie die Forscher:innen mit den Daten umgehen und was sie daraus ablesen. Dieser Anspruch ist erst mal hoch und ungewöhnlich in der Wissenschaftsgemeinschaft, in der Ergebnisse vor allem für andere Wissenschaftler:innen publiziert werden – und nicht so, dass ein durchschnittlicher interessierter Laie sie versteht. Doch die Kommunikation mit der „Community“ der freiwilligen Spender:innen lief nicht immer so gut.
Bereits zum Start der App am 7. April hatte es viel Kritik gegeben. Der Quellcode der App war nicht öffentlich zugänglich, weil ein Berliner Start-up die Software entwickelt hatte und dem RKI zur Verfügung stellte. So mussten sich Nutzer:innen auf die Versprechen der Beteiligten verlassen, dass ihre Daten gut geschützt seien.
Eine unabhängige Untersuchung von drei IT-Experten des Chaos Computer Clubs hatte kurz darauf ergeben, dass die App „zahlreiche technische und organisatorische Mängel“ aufweist und der Zugriff auf die hochsensiblen Daten keineswegs so begrenzt ist, wie das RKI – und die Datenschutzerklärung der App – dies darstellten. So holte sich das RKI die Daten der meisten Nutzer:innen nicht wie versprochen vom Smartphone, sondern direkt von den Anbietern der Fitnesstracker, wodurch auch Klarnamen und weitere Daten der Spender:innen auf den Servern des RKI landeten. Dieser Zugriff wäre auch nach Deinstallation der App bestehen geblieben. Auch wurden die Daten nicht bereits auf dem Telefon pseudonymisiert, sondern erst auf den Servern des RKI. Einige dieser Probleme haben die Entwickler der App inzwischen behoben.

Bisher keine Erkenntnisse über Dunkelziffern
Es ist also eine Menge Vertrauen verspielt worden in diesem Verfahren, dass nun zurück gewonnen werden muss. Und vor allem werden die Forscher:innen nun die Sinnhaftigkeit der Datenspende unter Beweis stellen müssen. Die bislang veröffentlichten Karten leisten das noch nicht.
Wirklich interessant wird es erst im nächsten Schritt. Dann wird sich nämlich zeigen müssen, ob die Daten tatsächlich dazu dienen können, Dunkelziffern der Infektion auszumachen und neue Infektionsherde früher auszumachen als mit den bisherigen Methoden der Erfassung. Kurz: Ob sich die Herausgabe der sehr persönlichen Daten der Spender:innen überhaupt gelohnt hat. Ob Ergebnisse in diese Richtung auch veröffentlicht werden? Das muss noch entschieden werden, sagt Brockmann. Erst mal müsse sich zeigen, ob die Prognosen überhaupt funktionieren.